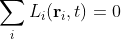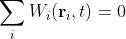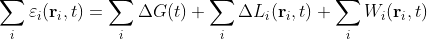Fig. 9.1: Record 1.
First a test. Look at the dataset above (Fig. 9.1) and the one below (Fig. 9.2). Can you tell which one is a real set of temperature data and which one is fake?

Fig. 9.2: Record 2.
Okay, so actually it was a trick question because they are both real sets of data. In fact they are both from the same set of station data, and they are partially from the same time period as well, but there is clearly a difference. The difference is that the data in Fig. 9.1 above is only a small part of the actual temperature record but the data from Fig. 9.2 is from the entire record. The data in Fig. 9.1 is taken from the Christchurch station (Berkeley Earth ID - 157045) and is monthly data for the period 1974 - 1987. The data in Fig. 9.2 is from the same record but for the time interval 1864 - 2013: it has also been smoothed with a 12 month moving average. Yet they look the very similar in terms of the frequency and height of their fluctuations - why? Well, what you are seeing here is an example of self-similarity or fractal behaviour. The temperature record for Christchurch is a one-dimensional fractal, and so for that matter is every other temperature record.
Self-similarity is common in nature. You see it everywhere from fern leaves and cauliflowers to clouds and snowflakes. It is observed when you magnify some objects and look at them in greater detail, only to find, to your surprise, that the detail looks just like a smaller version of the original object. This is known as self-similarity: the object looks like itself but in microcosm. It is also an example of scaling behaviour. There is usually a fixed size ratio between the original and the smaller copies from which it is made.
In order to make the smoothed data in Fig. 9.2 look similar to the original data in Fig. 9.1 two scaling adjustments were made. First the time scale on the horizontal axis in Fig. 9.2 was shrunk by a factor of twelve. This is to compensate for the smoothing process which effectively combines twelve points into one. The second was to scale up the temperature axis in Fig. 9.2 by a factor 12 0.275. The reason for the power of 0.275 will become apparent shortly, but it is important as it has profound implications for the noise level we see in temperature records over long time periods (i.e. centuries).
To demonstrate the scaling behaviour of the temperature record we shall do the following. First we smooth the data with a moving average of length say two points and then calculate the standard deviation of the smoothed data. Then we repeat this for the original data, but with a different number of data points in the moving average and again calculate the standard deviation of the new smoothed data. After doing this for six or seven different moving averages we plot a graph of the logarithm of the standard deviation versus log(N) where N is the number of points used each time for the moving average. The result is shown below in Fig. 9.3.

Fig. 9.3: Plot of the standard deviation of the smoothed anomaly data against the smoothing interval N for temperature data from Christchurch (1864-2013).
The important feature of the graph in Fig. 9.3 is that the data lies on an almost perfect straight line of slope -0.275 (remember that number)? I have to confess that even I was shocked by how good the fitting was when I first saw it, particularly given how imperfect temperature data is supposed to be. What this graph is illustrating is that as we smooth the data by a factor N, the noise level is reducing by a factor N-0.275. But is this reproducible for other data? Well the answer appears to be, yes.

Fig. 9.4: Plot of the standard deviation of the smoothed anomaly data against the smoothing interval N for temperature data from Auckland (1853-2013).
The graph above (Fig. 9.4) shows the same scaling behaviour for the station at Auckland (Berkeley Earth ID = 157062) while the one below (Fig. 9.5) illustrates it for the station at Wellington (Berkeley Earth ID = 18625). The gradients of the best fit lines (i.e. the power law index in each case) are -0.248 and -0.235 respectively. This suggests that the real value is probably about -0.25.

Fig. 9.5: Plot of the standard deviation of the smoothed anomaly data against the smoothing interval N for temperature data from Wellington (1863-2005).
But it is the implications of this that are profound. Because the data is such a perfect fit in all three cases, we can extrapolate to longer smoothing operations such as one hundred years. That corresponds to a scaling term of 1200 (because it is equal to 1200 months and thus is 1200 greater in period than the original data) and a noise reduction of 1200 0.25 = 5.89. In other words, the noise level on the underlying one hundred year moving average is expected to be about six times less than for the monthly data. This sounds like a lot but the monthly data for Christchurch has a noise range of up to 5 °C (see Fig. 9.6 below), so this implies that the noise range on a 100 year trend will still be almost 1 °C. Now if that doesn’t grab your attention, I have to wonder what will? Because it implies that the anthropogenic global warming (AGW) that climate scientists think they are measuring is probably all just low frequency noise resulting from the random fluctuations of a chaotic non-linear system.

Fig. 9.6: The temperature anomaly data from Christchurch (1864-2013) plus a 5-year smoothing average.
What we are seeing here is a manifestation of the butterfly effect which, put simply, says that there is no immediate causal link between some current phenomena such as the temperature fluctuations we see today and current global events. This is because the fluctuations are actually the result of dynamic effects that played out long ago but which are only now becoming visible.

Fig. 9.7: Typical mean station temperatures for each decade over time.
To illustrate the potential of this scaling behaviour further we can use it to make other predictions. Because the temperature record exhibits self-similarity on all timescales, it must do so for long timescales as well, such as centuries. So we can predict what the average temperature over hundreds of years might look like (qualitatively but not precisely) just by taking the monthly data in Fig. 9.6, expanding the time axis by a factor of 120 and shrinking the amplitude of the fluctuations by a factor of 120 0.25 = 3.310. The result is shown in Fig. 9.7 above. Because of the scaling by a factor of 120, each monthly data point in Fig. 9.6 becomes a decade in Fig. 9.7. The data in Fig. 9.7 thus indicates that the average temperature for each decade can typically fluctuate by about ±0.5 °C or more over the course of time.

Fig. 9.8: Typical mean station temperatures over 100 years over time.
Then, if we smooth the data in Fig. 9.7, we can determine the typical fluctuations over even longer timescales. So, smoothing with a ten point moving average will yield the changes in mean temperature for 100 year intervals as shown in the graph above (Fig. 9.8). This again shows large fluctuations (up to 0.5 °C) over large time intervals. But what we are really interested in from a practical viewpoint is the range of possible fluctuations over 100 years as this corresponds to the timeframe most quoted by climate scientists.
To examine this we can subtract from the value at current time t the equivalent value from one hundred years previous, i.e. ∆T = T(t) - T(t-100).

Fig. 9.9: Typical change in the 100-year mean temperature for a time difference of 100 years.
So, as an example we may wish to look at the change in mean temperature from different epochs, say from one century to the next. Well the data in Fig. 9.9 shows just that. Each data point represents difference between the mean temperature over a hundred years at that point in time with the same value for a hundred years previous. Despite the large averaging periods we still see significant temperature changes of ± 0.25 °C or more. However, if we compare decades in different centuries it is even more dramatic.
For example, Fig. 9.10 below predicts the range of changes in the average decadal temperatures from one century to the next, in other words, the difference between the 10-year mean temperature at a given time t and the equivalent decadal mean for a time one hundred years previous. What Fig. 9.10 indicates is that there is a high probability that the mean temperature in the 1990s could be 0.5 °C higher or lower that the mean temperature in the 1890s, and this is just as a consequence of low frequency noise.

Fig. 9.10: Typical change in mean decadal temperature for a time difference of 100 years.
So why have climate scientists not realized all this? Maybe it's because their cadre comprise more geography graduates and marine biologists than people with PhDs in quantum physics. But perhaps it is also due to the unique behaviour of the noise power spectrum.
If the noise in the temperature record behaved like white noise it would have a power spectrum that is independent of frequency, ω. If we define P(ω) to be the total power in the noise below a frequency, ω, then the power spectrum is the differential of P(ω). For white noise this is expected to be constant across all frequencies up to a cutoff frequency ωo.

(9.1)
This in turn means that P(ω) has the following linear form up to the cutoff frequency ωo.
P(ω) = aω
(9.2)
where a is a constant. The cutoff frequency is the maximum frequency in the Fourier spectrum of the data and is set by the inverse of the temporal spacing of the data points. If the data points are closer together then the cutoff frequency will be higher. Graphically P(ω) looks like the plot shown below in Fig. 9.11, a continuous horizontal line up to the cutoff frequency ωo.

Fig. 9.11: The frequency dependent power function P(ω) for white noise.
The effect of smoothing with a moving average of N points is to effectively reduce the cutoff frequency by a factor of N because you are merging N points into one. And because the noise power is proportional to the noise intensity, which is proportional to the square of the noise amplitude, this means that the noise amplitude (as well as the standard deviation of the noise) will reduce by a factor equal to √N when you smooth by a factor of N.
For a 100-year smoothing the scaling factor compared to a monthly average is 1200, and so the noise will therefore reduce by a factor of 1200 0.5 = 34.64 . That means the temperature fluctuations will be typically less than 0.1 °C. This is probably why climate scientists believe that the long term noise will always be smoothed or averaged out, and therefore why any features that remain in the temperature trend must be "real". The problem is, this does not appear to be true.
Instead the standard deviation varies as N -0.25. So the intensity of the noise varies as N -0.5 and P(ω) will increase as √N. It therefore follows that the power spectrum is not independent of frequency as is the case for white noise, but instead varies with frequency as

(9.3)
and P(ω) will look like the curve shown in Fig. 9.12 below.

Fig. 9.12: The frequency dependent power function P(ω) for temperature data.
The net result is that the random fluctuations in temperature seen over timescales of 100 years or more are up to six times greater in magnitude than most climate scientists probably think they will be. So the clear conclusions is this: most of what you see in the smoothed and averaged temperature data is noise not systemic change (i.e. warming). Except, unfortunately, most people tend to see what they want to see.